O checkpointing salva um snapshot do estado de execução durante uma execução para que uma crew, flow ou agente possa retomar após uma falha ou ser bifurcado em uma branch alternativa.Documentation Index
Fetch the complete documentation index at: https://crewai-lorenze-feat-conversational-flows.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Explicação
Como o checkpointing funciona: eventos, armazenamento e herança.
Tutorial
Um passo a passo de 5 minutos: executar, interromper, retomar.
Guias de uso
Receitas focadas em tarefas para fluxos comuns.
Referência
CheckpointConfig, eventos, provedores e CLI.Explicação
O que é um checkpoint
Um checkpoint captura tudo o que o CrewAI precisa para recriar uma execução em andamento: o estado completo da crew, flow ou agente — configuração, memória e fontes de conhecimento dos agentes, progresso das tarefas, saídas intermediárias, estado interno e atributos — junto com os inputs do kickoff, o histórico de eventos até aquele ponto e um ID de linhagem que liga o checkpoint à execução de origem. Restaurar reconstrói esse estado e continua. Tarefas concluídas são puladas, memória e conhecimento são reidratados, e o trabalho downstream roda contra as mesmas saídas que a execução original produziu. Fazer fork executa a mesma restauração sob uma nova linhagem, para que a nova branch e a execução original gravem checkpoints lado a lado sem sobrescrever uma a outra.Quando os checkpoints são gravados
O checkpointing é orientado a eventos. O runtime se inscreve nos eventos selecionados emon_events e grava um checkpoint sempre que um é disparado. O padrão task_completed produz um checkpoint por tarefa finalizada — um equilíbrio razoável entre granularidade e uso de disco. Eventos de alta frequência como llm_call_completed estão disponíveis para recuperação mais granular, mas gravam muito mais arquivos.
Armazenamento
Dois provedores acompanham o CrewAI:JsonProvidergrava um arquivo por checkpoint. Legível e fácil de inspecionar.SqliteProvidergrava em um único banco SQLite. Melhor para checkpointing de alta frequência.
max_checkpoints está definido.
Gravações de checkpoint automáticas (acionadas por evento) são best-effort: uma falha é registrada em log e a execução continua. Chamadas manuais a
state.checkpoint() e state.acheckpoint() relançam a exceção.Modelo de herança
Crew, Flow e Agent aceitam um argumento checkpoint. Filhos herdam do pai a menos que definam seu próprio valor ou passem False para desativar. Ative o checkpointing uma vez na crew e todos os agentes participam, ou exclua um agente seletivamente.
Tutorial: Retomar uma crew com falha
Este passo a passo leva cerca de 5 minutos. Você executará uma crew de duas tarefas, a interromperá no meio e a retomará a partir do checkpoint salvo.Execute e interrompa após a primeira tarefa
Ctrl+C após a primeira tarefa concluir. Em ./.checkpoints/, um arquivo <timestamp>_<uuid>.json é o checkpoint.Guias de uso
Ativar checkpointing com padrões
Ativar checkpointing com padrões
./.checkpoints/ em cada task_completed.Personalizar armazenamento e frequência
Personalizar armazenamento e frequência
Escolher um provedor de armazenamento
Escolher um provedor de armazenamento
Desativar um agente específico
Desativar um agente específico
Fazer fork em uma nova branch
Fazer fork em uma nova branch
fork() restaura um checkpoint sob uma nova linhagem para que a nova execução não colida com a original.branch é opcional; um é gerado se omitido.Checkpoint em Crew, Flow ou Agent
Checkpoint em Crew, Flow ou Agent
- Crew
- Flow
- Agent
task_completed.Gravar um checkpoint manualmente
Gravar um checkpoint manualmente
Registre um handler em qualquer evento e chame Um argumento
state.checkpoint().state é fornecido automaticamente quando o handler recebe três parâmetros. Veja Event Listeners para o catálogo completo de eventos.Navegar, retomar e fazer fork pela CLI
Navegar, retomar e fazer fork pela CLI
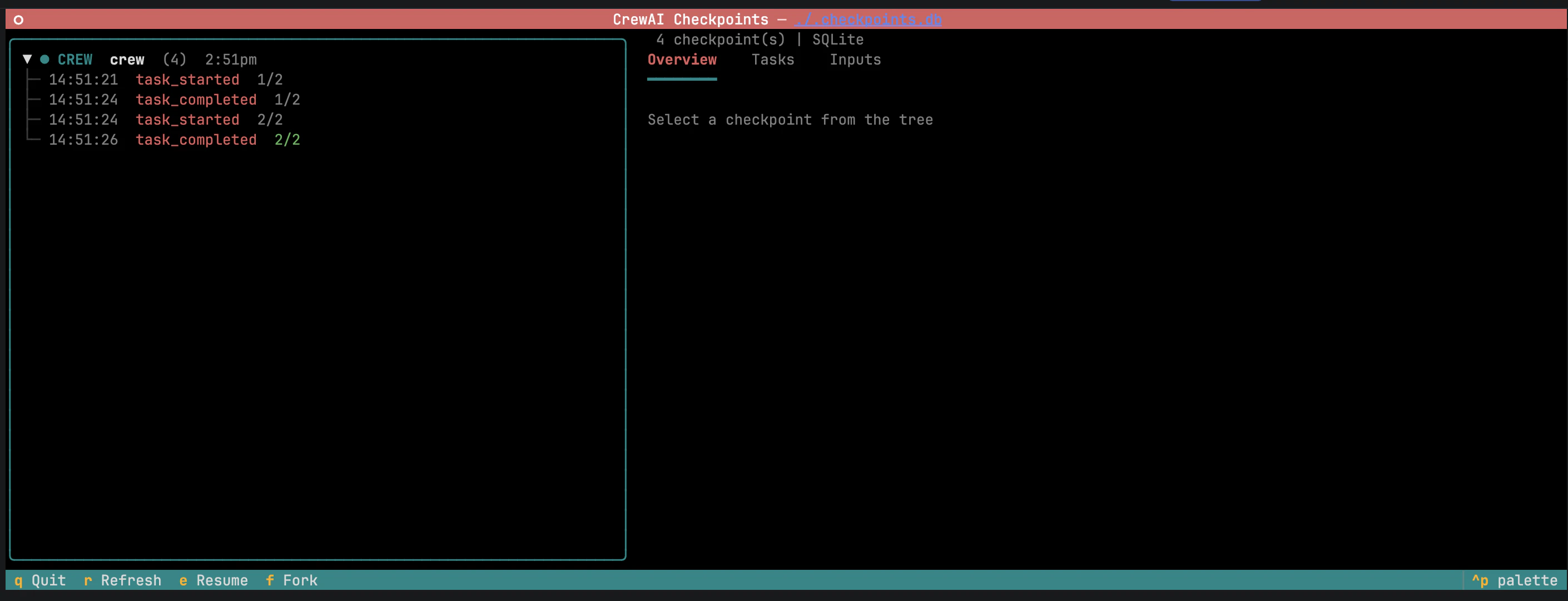
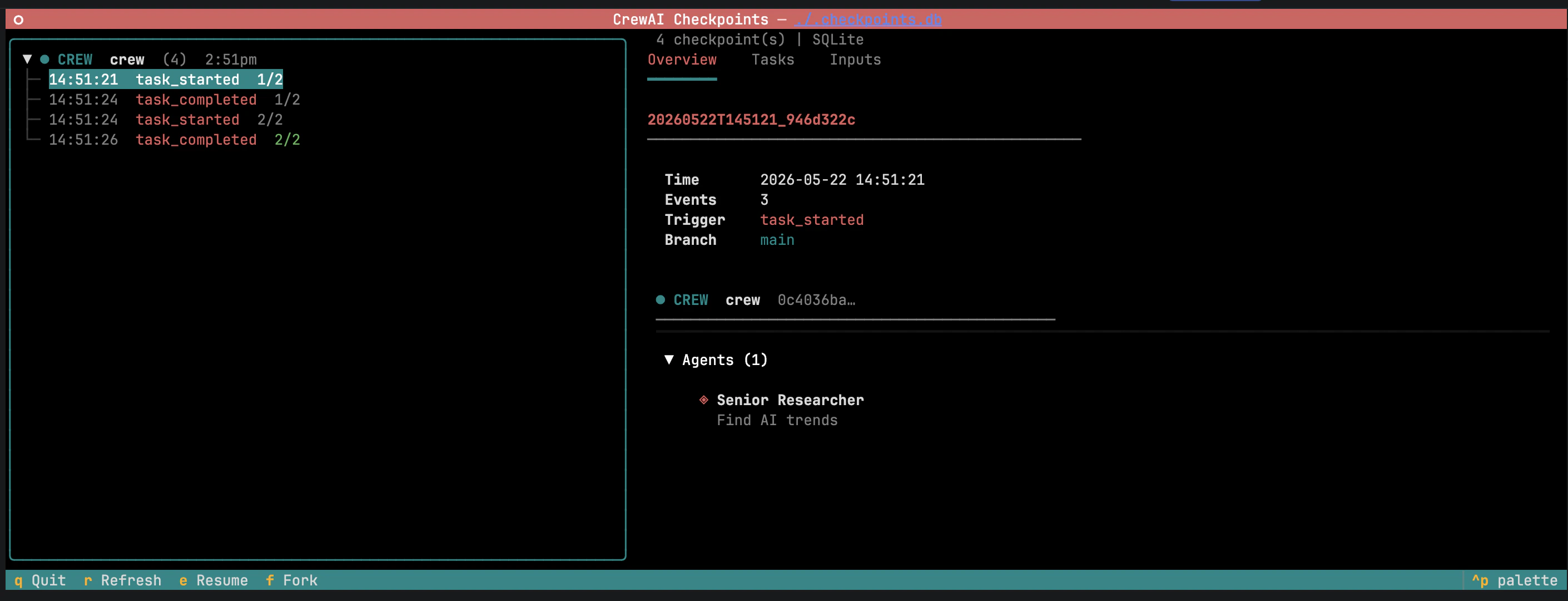
-
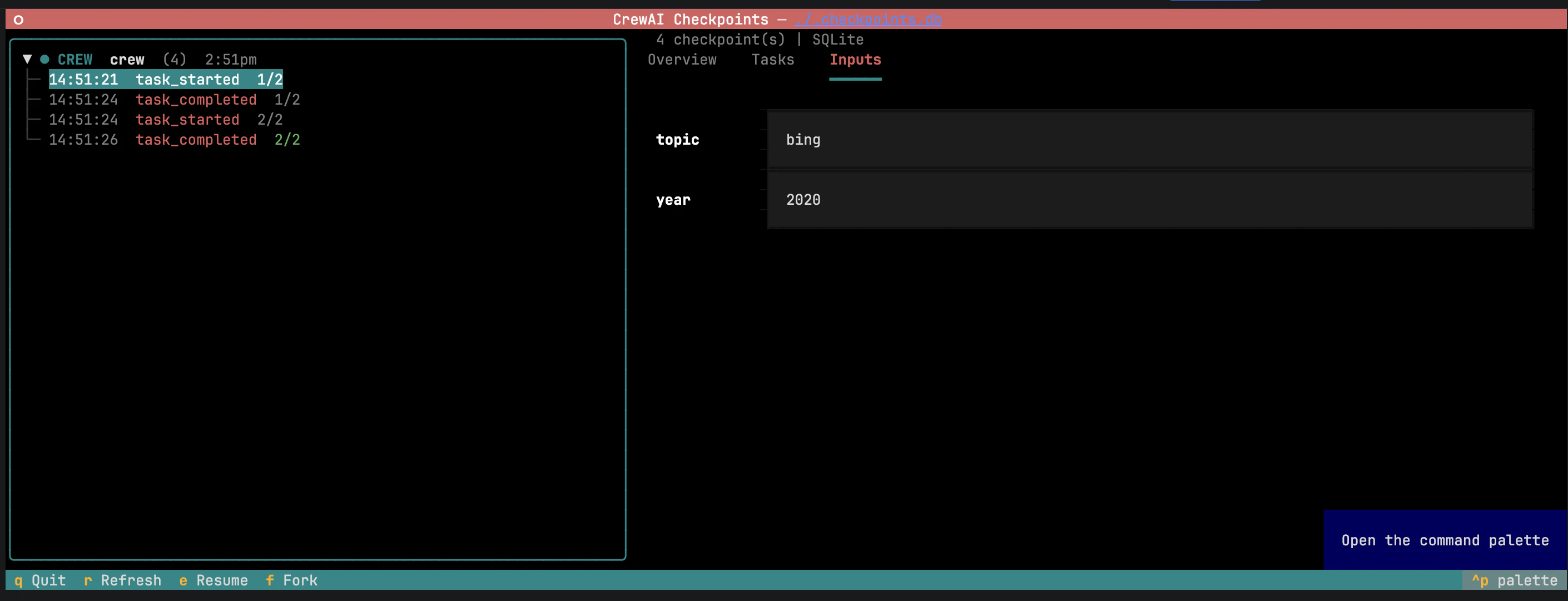
Inputs — os inputs originais do kickoff, preenchidos e editáveis.
-
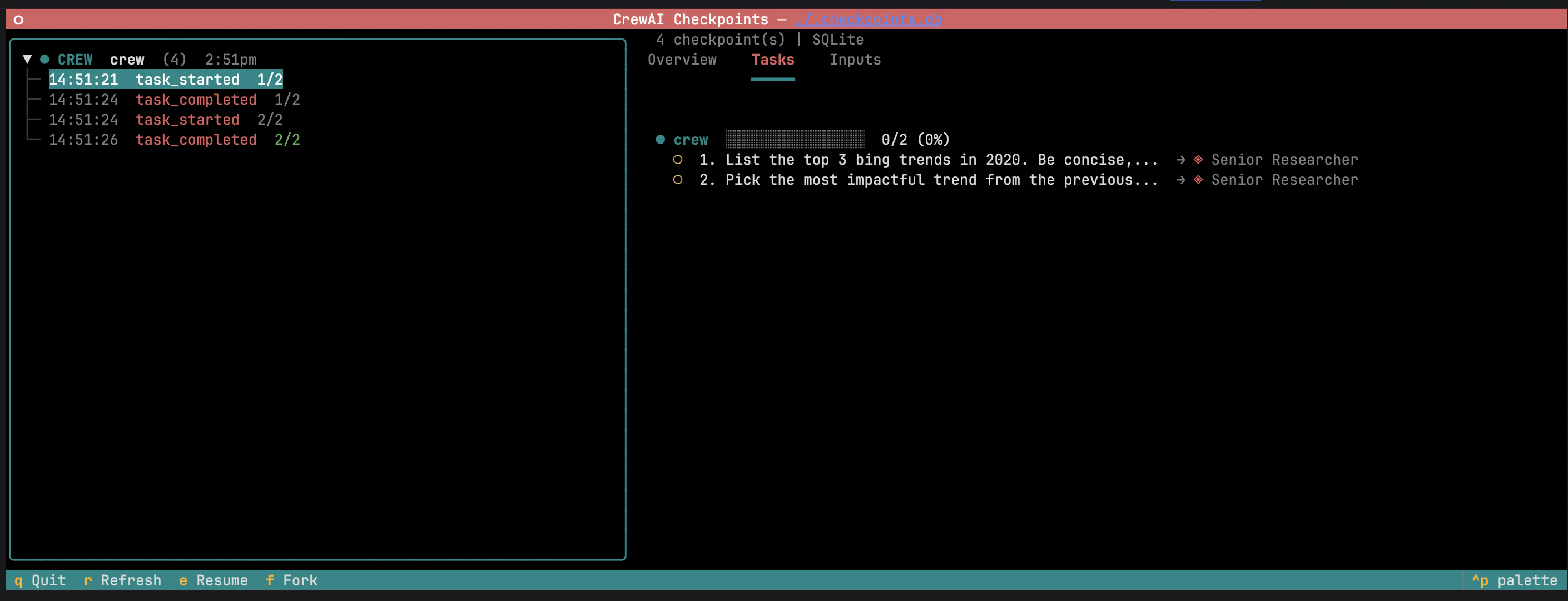
Saídas das tarefas — saídas das tarefas concluídas. Editar uma saída e pressionar Fork invalida tarefas downstream para que sejam reexecutadas com o contexto modificado.
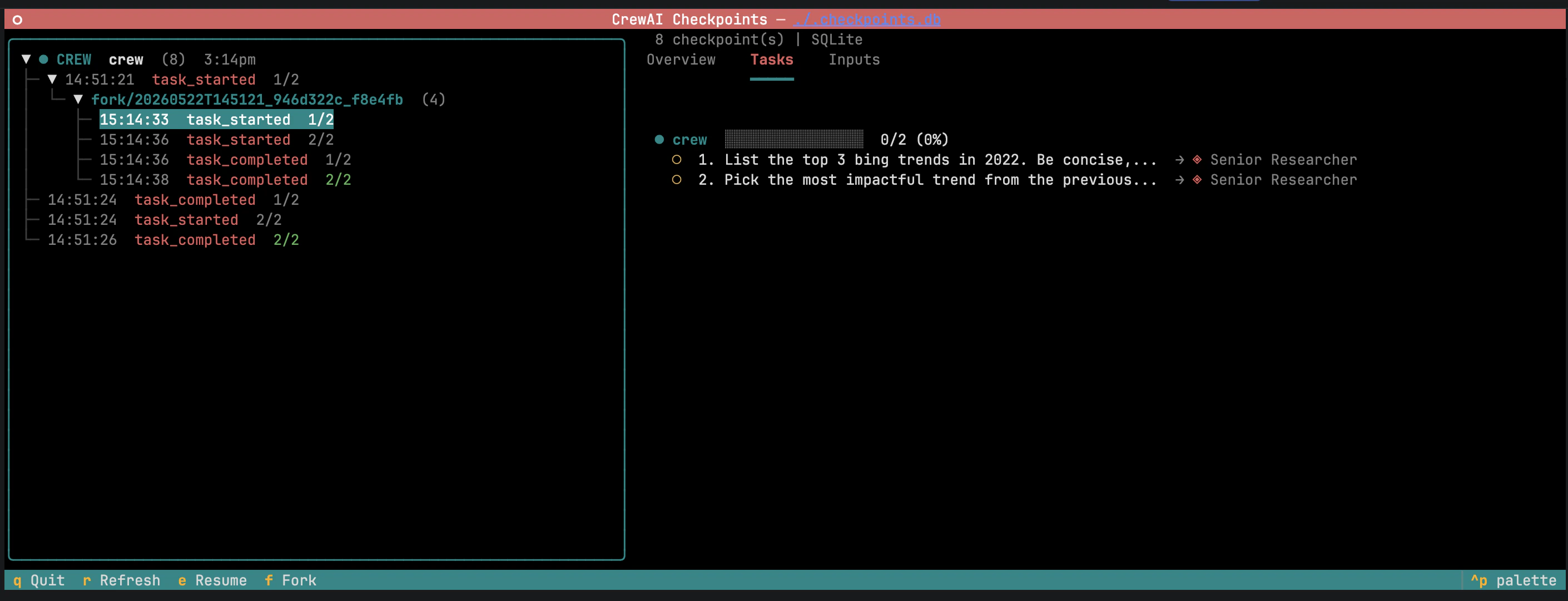
Inspecionar checkpoints sem a TUI
Inspecionar checkpoints sem a TUI
Referência
CheckpointConfig
Destino do armazenamento. Diretório para
JsonProvider, caminho de arquivo de banco para SqliteProvider.Tipos de evento que disparam um checkpoint.
CheckpointEventType é um Literal — seu type checker autocompleta e rejeita valores não suportados. Veja tipos de evento para a lista completa.Backend de armazenamento.
JsonProvider ou SqliteProvider.Máximo de checkpoints a reter. Os mais antigos são removidos após cada gravação.
Checkpoint a restaurar quando passado via
from_checkpoint.Valores do campo checkpoint
Aceito por Crew, Flow e Agent.
Herda do pai.
Ativa com padrões.
Desativação explícita. Interrompe a herança.
Configuração personalizada.
Tipos de evento
on_events aceita qualquer combinação de valores CheckpointEventType. O padrão ["task_completed"] grava um checkpoint por tarefa finalizada; ["*"] corresponde a todos os eventos.
Provedores de armazenamento
Um arquivo por checkpoint, nomeado
<timestamp>_<uuid>.json dentro de location.Arquivo de banco único em
location com journaling WAL.CLI
| Comando | Propósito |
|---|---|
crewai checkpoint | Inicia a TUI; detecta o armazenamento automaticamente. |
crewai checkpoint --location <path> | Inicia a TUI em uma localização específica. |
crewai checkpoint list <path> | Lista checkpoints. |
crewai checkpoint info <path> | Inspeciona um arquivo de checkpoint ou a entrada mais recente em um banco SQLite. |